Un peu d'histoire pour comprendre :
L'informatique s'est d'abord développée autour du concept de l'ordinateur
central tout puissant "Big Brother" ou "HAL9000" dans "2001,
l'odyssée de l'espace". C'est ce qui a donné naissance aux
grands systmes centraux comme l'IBM 360 ou Multics vers la fin des années
70. Les terminaux ne communiquent entre eux qu'au travers de la machine centrale.
Ce concept a ensuite évolué vers un concept quasi-identique, le
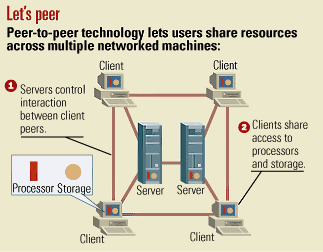
modèle client/serveur où les clients sont attachés au serveur
par réseau au travers d'un logiciel propriétaire. Cependant, dans
la foulée de mai 68, des informaticiens un peu visionnaires conçoivent
un systme -Unix- pour des machines plus petites avec un mode de communication
d'égal à égal pour partager des ressources sur le réseau
-ARPANET-, l'anctre d'Internet. Le protocole de communication de l'Internet
a été conu dès le début comme un système
symétrique peer-to-peer. Les premires "killer applications"
de l'Internet -FTP pour l'échange de fichiers ou Telnet pour utiliser
une machine à distance- étaient en fait des applications client/serveur
avec cependant une nuance : chaque système pouvait être à
la fois client ET serveur. En effet, la beauté du protocole TCP/IP est
d'être parfaitement symétrique. Les premières applications
de l'Internet qui utilisent réellement cette symétrie ont été
les serveurs de News et les serveurs de noms de domaines (DNS). Dans les 2 cas,
le problme était un problème de partage de fichiers. Ceci a été
résolu par une coopération entre machines dont chacune sert en
priorité l'espace dont elle est responsable. Il est intéressant
de noter que dans les 2 cas, c'est une structure hiérarchique qui a permis
de résoudre ce partage d'espace (talk.philosophy.humanism pour les newsgroups
ou www.figer.com pour les DNS). Au début de l'explosion de l'Internet
dans le grand public, le navigateur web et d'autres applications ont été
construites sur le modèle simpliste du client/serveur : on pose une question
et on attend la réponse. Pire, les fournisseurs d'accès à
Internet ont attribué des adresse IP temporaires aux utilisateurs qui
se connectaient par téléphone et les firewalls et autres NAT ont
achevé de transformer le réseau Internet en un systme essentiellement
client/serveur.
Les 2 caractéristiques du peer-to-peer
:
Le terme Peer-to-Peer n'aide pas à
clarifier les choses. Le jeu en réseau Doom, l'émail ou le téléphone
peuvent être vus comme des systmes peer-to-peer (on échange des
informations entre pairs) alors que Napster qui a popularisé le concept
est construit autour d'un serveur central.
Le vrai changement, c'est la nature des éléments qui constituent
les réseaux peer-to-peer. Dans le passé, les centaines de millions
d'ordinateurs connectés à Internet de manière intermittente
ne faisaient pas partie du réseau. Ils n'avaient pas d'adresse IP fixe
sur le réseau connue dans les DNS. Peer-to-peer désigne donc une
classe d'applications qui tire partie des ressources matérielles ou humaines
qui sont disponibles au bord de l'Internet. Comme ces ressources ont une connectivité
instable ou des adresses IP variables, elles fonctionnent de manière
autonome, indépendamment de systèmes centraux comme les DNS. Ce
qui a rendu Napster et des systèmes similaires populaires, c'est le fait
de tirer partie de ressources qui étaient auparavant inutilisées
en tolérant et même en tirant partie d'une connectivité
aléatoire.
Un
vrai système peer-to-peer se reconnaît donc par les 2 caractéristiques
suivantes :
• Est-ce que le système permet à chaque pair de se connecter
de manière intermittente avec des adresses IP variables ?
• Est-ce que le système donne à chaque pair une autonomie
significative ?
Si la réponse est oui à ces 2 questions, le système est
un système peer-to-peer.
Une autre manière de distinguer un système peer-to-peer
est de raisonner en terme de "propriété". Il faut remplacer
la question "Est-ce que les pairs peuvent échanger des informations
?" par la question "Qui possède les ressources qui font tourner
le système ?". Dans un système comme Yahoo!, l'essentiel
des ressources est possédé par Yahoo! tandis que dans un système
comme Napster, l'essentiel des ressources est possédé par les
utilisateurs de Napster. Dans les vrais systèmes peer-to-peer, on ne
se contente pas de décentraliser les fonctions mais aussi les coùts
et les charges d'administration.
Avec un calcul très conservateur, 100 millions de PC connectés
à Internet avec une puissance de 100Mhz et 100Mo de disques représentent
une puissance de dix milliard de Mhz et dix mille teraoctets de stockage. C'est
de ces ressources dont il faut tirer parti.
ICQ,
Seti@home, Napster et les autres :
ICQ a été en
1996 le premier système de messagerie instantanée et Chat sur
PC. Pour indiquer la présence d'utilisateurs connectés de manière
intermittente, ICQ a développé un système de répertoire
des utilisateurs dont l'adresse IP pouvait être mise à jour de
manière instantanée. C'est le même "truc" qui
est utilisé par Napster, Netmeeting ou Groove. Mais ce n'est pas la seule
solution : Gnutella et Freenet utilisent les adresses IP numériques,
United Devices et Seti@home donnent des rendez-vous périodiques aux utilisateurs.
Voici les principales caractéristiques de ces projets marquants.
ICQ,
les pionniers :
Quatre jeunes israéliens créèrent en juillet 1996 une société
Mirabilis Ltd devenue en juin 1998 ICQ lors du rachat par AOL.
Yair Goldfinger (26 ans,Chief Technology Officer), Arik Vardi (27 ans,Chief
Executive Officer), Sefi Vigiser (25 ans, President) et Amnon Amir (24 ans,
encore étudiant) constatèrent l'accroissement rapide du nombre
d'utilisateurs de l'Internet qui se connectaient à des serveurs web.
Bien que ces utilisateurs soient tous ensemble connectés sur le mme réseau,
ils n'étaient pas interconnectés. Le chaînon manquant, c'était
le moyen de localiser son correspondant et d'établir une canal de communication
peer-to-peer avec lui. Développé en quatre mois et proposé
en téléchargement gratuit en Novembre 1996, le produit ICQ ("I
seek you") se répandit comme une traînée de poudre
pour atteindre plus de 850000 utilisateurs en mai 1997. Il est devenu et resté
le programme le plus téléchargé sur l'Internet jusqu'à
l'arrivée des programmes d'échanges de musique autour du .mp3.
Pour identifier les utilisateurs, ICQ leur attribue un numéro. Comme
vous pouvez le constater ici , un de mes numéros est un numéro
à 6 chiffres (720494) me classant parmi les premiers utilisateurs des
premiers mois. ICQ a ensuite été imité avec AOL messenger,
Netscape messenger, Yahoo messenger, MSN messenger, etc. fragmentant la communauté
des utilisateurs. Une initiative intéressante, c'est celle de Jabber
qui fournit un produit gratuit interopérable avec tous les autres.
Seti@Home, l'ordinateur le plus puissant
du monde :
Sommes-nous seuls dans l'Univers ? Cette question hante l'humanité depuis
la nuit des temps. Au début de 1960, le premier programme SETI
( Search for Extra Terrestrial Intelligence) a été lancé
en recherchant des signaux radio émis par les galaxies. Le financement
de ces programmes a toujours été aléatoire car il fallait
en effet disposer d'une très grosse puissance de calcul. En 1995, David
Gedye eut l'idée d'utiliser la puissance inutilisée des PCs connectés
à Internet. Avec 3 autres collègues de l'université de
Berkeley, ils présentrent l'idée sur un site web au début
de 1998. Ils recueillirent l'inscription de plus de 400000 volontaires. Le premier
logiciel client fut disponible le 17 mai 1999. Aujourd'hui, 14 octobre 2001,
il y a 3311948 participants dans 226 pays. Le nombre d'instructions exécutées
a dépassé 1 ZettaFLOP ( 10 puissance 21 ) ce qui en fait le plus
gros calcul jamais effectué. Dans les dernires 24 heures, la puissance
de calcul a été de 88 TeraFlops/seconde. Le plus gros ordinateur
du Monde est actuellement l'ASCI White d'IBM : 110 Millions de dollars, 106
tonnes et seulement 12.3 teraFlops/s. Pour moins de 1% du coût, le programme
Seti@Home est beaucoup plus puissant.
Même si on ne trouve pas d'extraterrestres, ce programme aura démontré
comment les techniques logiciels pouvaient transformer un grand nombre d'ordinateurs
individuels peu fiables et connectés de manire intermittente en un système
très rapide et très fiable.
La saga Napster :

Napster est sans doute le plus connu des systmes peer-to-peer.
Il permet de partager votre collection de CD avec celle de 50 millions d'utilisateurs.
Les techniques de compression, en particulier le mp3 , avaient permis de stocker
sur PC des fichiers musicaux et de les échanger sur Internet. Avec le
logiciel Napster, dès que vous vous connectez sur Internet, vous envoyez
au serveur la liste de vos titres. Ceux-ci sont alors stockés dans un
répertoire. Si vous recherchez un titre particulier, Napster vous fournit
la liste des utilisateurs en ligne qui le possèdent et vous pouvez directement
le télécharger depuis l'autre PC par une liaison peer-to-peer.
En elle même, l'activité de Napster n'avait rien d'illégal
puisque les fichiers de musique ne passaient pas par le serveur. Il a fallu
à la RIAA (Recording Industry association of America) plusieurs tentatives
avant d'obtenir un jugement défavorable à Napster. On peut se
demander pourquoi la RIAA ne fait pas de procès, sur les mêmes
bases, aux fabricants de graveurs de CD ou de cassettes. L'interdiction de mettre
dans son catalogue des titres de chansons avec copyright a signé l'arrêt
de mort de Napster qui est actuellement fermé. Immédiatement des
dizaines de Napster-bis se sont développés, dont certains comme
AudioGalaxy satellite ou MusicCity Morpheus ont un succès qui dépasse
de loin celui de Napster. La RIAA a du pain sur la planche.
Les autres :
Chacune des technologies précédentes a engendré une nombreuse
descendance :
• AOL Instant messenger
, Yahoo!messenger , Netscape
messenger , MSN messenger
,.. pour ICQ
• Distributed.net , United Devices , Internet Virtual Machine , Multi
Agent Systems ,... pour Seti@Home
• Gnutella , Gnutellanews ou Gnutelliums, AudioGalaxy satellite , MusicCity
Morpheus ,.. pour Napster.

Des dizaines de systèmes utilisent ces principes comme en particulier
un système destiné à éviter la censure des documents
sur Internet Publius . Le paradigme P2P n'a pas seulement des conséquences
techniques : il déplace la puissance et en conséquence le pouvoir
d'organisations centralisées vers les individus.
Quel avenir pour le Peer-to-peer ?
Les définitions comme le peer-to-peer
ont peu d'intérêt pour prédire le futur d'une technologie.
Si on considre une définition comme le Multimédia, le futur au
début des années 90 était construit autour de CD-ROMs produits
par des professionnels ou de serveurs forteresses comme Compuserve. En quelques
années, le HTML est passé du stade inconnu à l'outil indispensable
du multimédia remplaçant les outils complexes de création
de CD-ROM ou les coûteuses expérimentations de télévision
interactive. Le HTML a réalisé ce tour de force sans R&D centralisée
ni coordination particulière ni motivation financière. En fait
le HTML a été imposé par les utilisateurs qui avaient trouvé
un moyen très simple de réaliser des pages Web sans le recours
à des professionnels ou à des outils compliqués. Ce qui
est important, pour prédire l'avenir d'une technologie, c'est sa vitesse
d'adoption par les utilisateurs. Et les utilisateurs n'adoptent pas une technologie
mais des applications. Le peer-to-peer permet d'introduire des applications
où l'utilisateur n'est pas seulement un consommateur mais aussi un fournisseur,
où la décentralisation n'est pas un objectif mais un outil, où
la puissance considérable de chaque PC est un peu mieux utilisée,
où ce qui compte ce n'est plus l'adresse physique de la machine mais
celle de l'utilisateur. Bref, un monde nouveau pour les applications qui sauront
en tirer partie.
© Jean-Paul Figer,1995-2003
Pour ceux qui veulent expérimenter cette technologie, il existe un excellent
produit gratuit pour se faire la main BadBlue .
![]()
![]()
